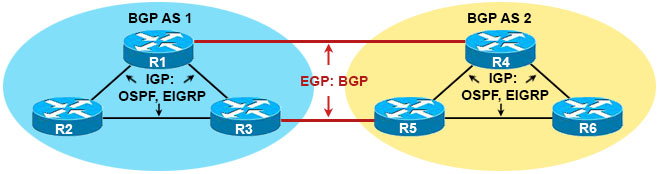
Here you will find answers to BGP Questions – Part 3
Question 1
Which option is true regarding the synchronization rule?
A. Do not use or internally advertise a route until the route is learned from a source other than BGP.
B. Do not use or advertise a route until the route is learned from a BGP peer.
C. Do not use or advertise routes marked PARTIAL.
D. Wait until a CONFIRM message is received before using routes from BGP neighbors.
Answer: A
Explanation
The complete synchronization rule is “A BGP router should not use, or advertise to an external neighbor, a route learned by IBGP, unless that route is local or is learned from the IGP.”
With the default of synchronization disabled, BGP can use and advertise to external BGP neighbors routes learned from an IBGP neighbor that are not present in the local routing table
The “synchronization” here means “synchronization between iBGP with its IGP (such as OSPF, EIGRP…)
You can disable synchronization if one of the following conditions is true:
Your AS does not pass traffic from one AS to another AS.
All the transit routers in your AS run BGP.
Note: BGP synchronization is disabled by default in Cisco IOS Software Release 12.2(8)T and later.
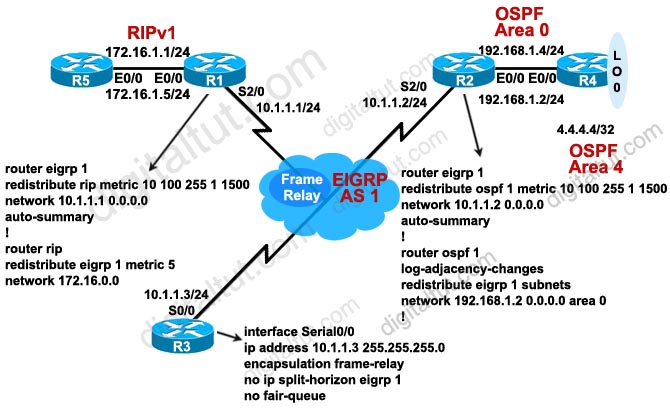
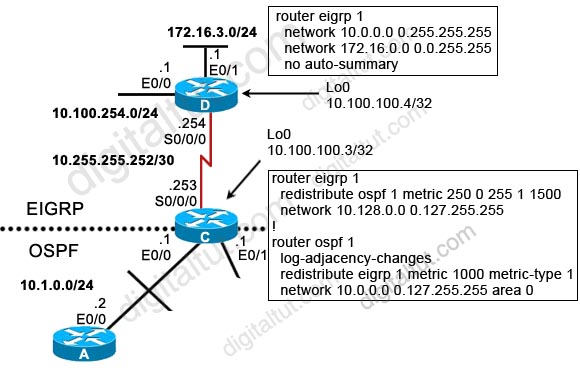
For more information about BGP Synchronization please read the explanation of Question 5 in this page. Also another good resource is : http://docwiki.cisco.com/wiki/Internetworking_Case_Studies_–_Using_the_Border_Gateway_Protocol_for_Interdomain_Routing#Synchronization
Question 2
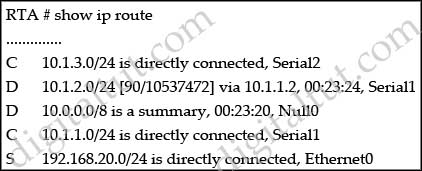
Refer to the exhibit. Router RT-1 and router RT-2 both advertise network 131.25.0.0/16 to router RT-3 via internal BGP. What is the reason that router RT-3 chose router RT-1 as its best path to network 131.25.0.0/16.
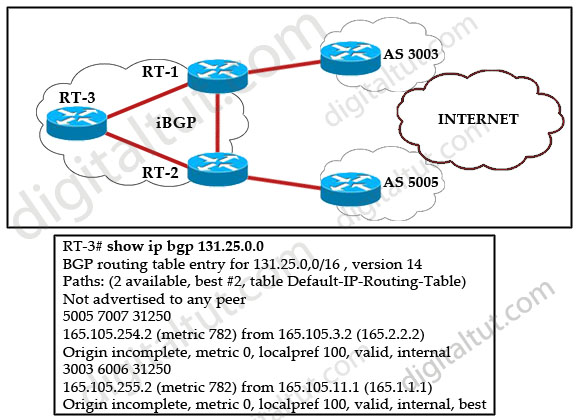
A. It advertises the best AS-path.
B. It advertises the best origin code.
C. It advertises the best MED.
D. It advertises the best local preference.
E. It has a better router ID.
F. It advertises a lower autonomous system.
Answer: E
Explanation
Recall the route selection decision process in BGP:
Consider only (synchronized) routes with no AS loops and a valid next hop, and then:
| Route selection decision process (from top to bottom) |
In this question… |
| Prefer highest weight (local to router) |
RT-3 is not an exit point |
| Prefer highest local preference (global within AS) |
same local preference of 100 |
| Prefer route originated by the local router (next hop = 0.0.0.0) |
both routes are from IBGP |
| Prefer shortest AS path |
same |
| Prefer lowest origin code (IGP < EGP ) |
both are incomplete (EGP > IGP > Incomplete) |
| Prefer lowest MED (exchanged between autonomous systems) |
both MEDs are 0 |
| Prefer EBGP path over IBGP path |
both are IBGP |
| Prefer the path through the closest IGP neighbor (IGP cost) |
not used because IBGPs are used |
| Prefer oldest route for EBGP paths. |
not used |
| Prefer the path with the lowest neighbor BGP router ID. |
the router-id 162.105.11.1 is lower than 165.105.3.2 |
| Prefer the path with the lowest neighbor IP address. |
|
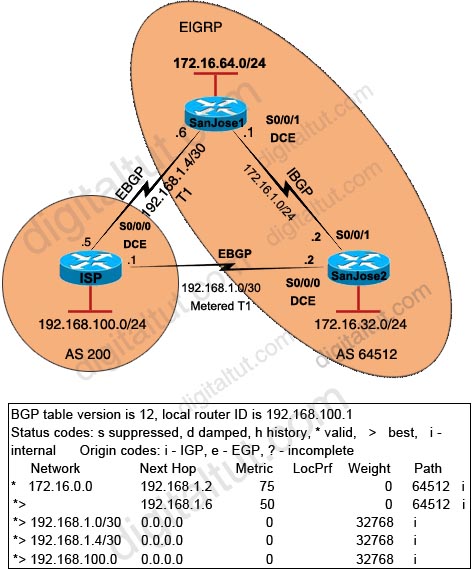
Question 3
Refer to the exhibit. Router RT-1 chooses one path to network 198.133.219.0/24. Indicate the reason Router RT-1 chooses this “best” path.
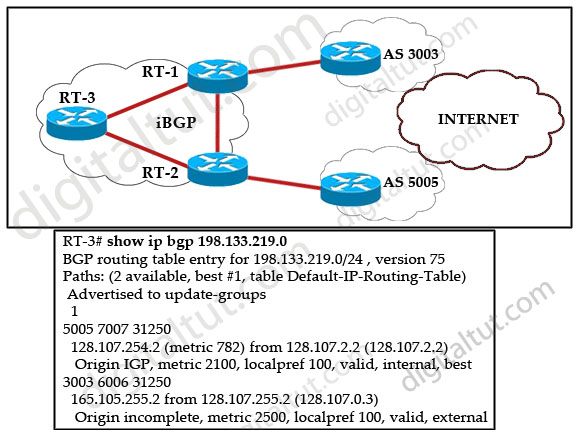
A. In making its decision about the best path, RT-1 gives precedence to the origin code.
B. In making its decision about the best path, RT-1 gives precedence to the BGP MED values.
C. IP address 128.107.2.2 is lower than 128.107.255.2.
D. In making its decision about the best path, RT-1 prefers the IGP metrics.
E. RT-1 prefers internal BGP routes.
F. IP address 128.107.254.2 is lower than 128.107.255.2.
Answer: A
Explanation
As explained in question 3, the IGP is preferred over incomplete.
Question 4
The Border Gateway Protocol (BGP) is the core routing protocol of the Internet. Refer to the exhibit. Routers A and B are running BGP but the session is active. What command needs to be added to establish the BGP session?

hostname A
!
interface loopback 0
ip address 10.10.10.2 255.255.255.255
!
interface serial 0/0
ip address 172.16.10.2 255.255.255.252
!
interface serial 0/1
ip address 172.16.10.5 255.255.255.252
!
router bgp 65444
neighbor 10.10.10.1 remote-as 65111
neighbor 10.10.10.1 update-source loopback 0
neighbor 10.10.10.1 ebgp-multihop |
A. ip route 10.10.10.1 255.255.255.255 s0/0
ip route 10.10.10.1 255.255.255.255 s0/ 1
B. no synchronization
C. network 10.10.10.0
D. neighbor 10.10.10.1 next-hop-self
Answer: A
Explanation
In this case we want to achieve load balancing so the loopback interface must be used to establish neighborship.
If we check the routing table of router A, we will see that there is no entry for the remote network 1.1.1.1/32 -> router A does not know how to reach the loopback interface on router B -> a TCP session can’t be established to router B. Therefore we need to tell router A a way to reach router B.
(Reference and a good resource: http://www.cisco.com/en/US/tech/tk365/technologies_tech_note09186a00800c95bb.shtml)
Question 5
Refer to the exhibit. Autonomous systems 200 and 300 have EBGP sessions established with their directly connected routers in autonomous system 100. IGP has been configured on all routers in autonomous system 100 and they successfully exchange routing updates. Traffic originated in autonomous system 200 cannot reach the destination autonomous system 300. What configuration should be done on the routers in autonomous system 100 in order for the traffic coming from autonomous system 200 to be forwarded to autonomous system 300?
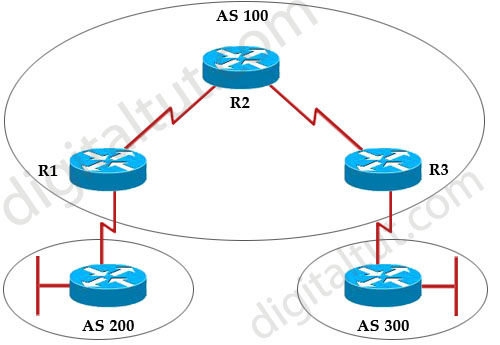
A. IBGP session must be established between routers R1 and R3, and the synchronization must be turned on.
B. IBGP session must be established between routers R1 and R3, and the synchronization must be turned off.
C. IBGP session must be established between routers R1 R2 and R2 R3. and the synchronization must be turned on.
D. IBGP session must be established between routers R1 R2 and R2 R3, and the synchronization must be turned off.
E. IBGP speakers within autonomous 100 must be fully meshed, and the synchronization must be turned on.
F. IBGP speakers within autonomous 100 must be fully meshed, and the synchronization must be turned off.
Answer: F
Explanation
The synchronization rule states that if an AS provides transit service to another AS, BGP should not advertise a route until all of the routers within the AS have learned about the route via an IGP. To understand why this rule exists, let’s take an example if this rule is not there.
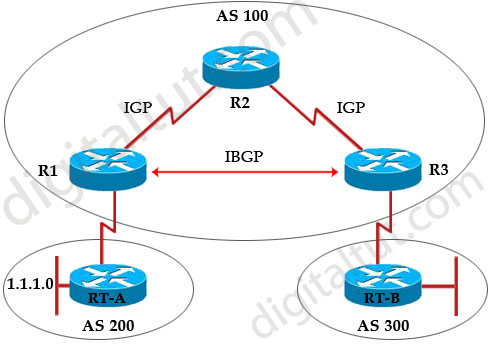
Suppose Rt-A wants RT-B to access its local LAN 1.1.1.0, so it advertises this network through R1. R1 and R3 are running IBGP so R1 sends this update to R3 through R2 (using the next-hop-self to use its own interface’s IP address). In turn, R3 announces to RT-B that it can reach 1.1.1.0 via R3.
Now Rt-B really wants to send traffic to 1.1.1.0 so it will send to R3. R3 does a look up and sees that the network can be reachable via R1. It then does a lookup for R1’s IP address and sees that it is reachable via R2 -> so it forwards packets to R2. But R2, running IGP (like OSPF), does not find an entry for 1.1.1.0 so R2 drops all the packets for that network – a black-hole is created!
That is why the BGP synchronization rule is born. With this rule, when R3 receives an advertisement for 1.1.1.0 from R1, it adds that route to its BGP table and before sending advertisement to RT-B, it first checks its IGP routing table to see whether an entry exists for that route. In this example, R3’s IGP routing table does not know how to reach 1.1.1.0 so R3 will not advertise this network to RT-B. This route is only advertised to RT-B when IGP makes an entry in the routing table for 1.1.1.0.
Well, now you understand the importance of BGP Synchronization rule but now I wish to explain why this rule causes trouble in fully-meshed IBGP!
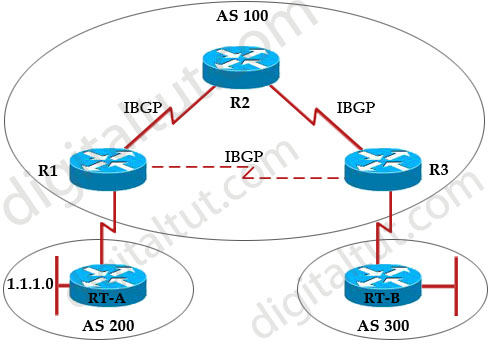
Synchronization prevents fully-meshed IBGP from working properly. Because no IGP is running so R3 cannot advertise any route to RT-B even if no black-hole exists in this topology.
Note: A “fully-meshed” can be a physical fully-meshed topology or a topology where all routers in the same AS established IBGP connections with each other (although they do not need to be directly connected). So in the topology above, the connection between R1 & R3 is represented by a dashed line, which means it can be physically connected or not (but an IBGP connection must be established on both routers).
Therefore if all routers in AS 100 is fully-meshed, the synchronization rule must be turned off -> F is correct.
Question 6
Which one of the following statements about BGP is FALSE?
A. BGP uses TCP port 179.
B. BGP ensures reliability of updates by using the reliable transport services of TCP.
C. The network command with the mask option never installs a prefix into the BGP table unless there is a matching prefix exists in the IP route table.
D. A TCP connection is required before exchanging updates.
E. BGP uses notification and the update messages to establish and maintain the BGP neighbor relationship.
Answer: E
Explanation
An underlying connection between two BGP speakers is established before any routing information is exchanged. This connection takes place on TCP port 179.
Unlike other routing protocols, the router must be manually configured with the neighbor information on both sides of the connection -> E is correct (which is FALSE in this question)
Question 7
Which BGP option is required when load sharing over multiple equal-bandwidth parallel links from a single CE router to a single ISP router over eBGP?
A. eBGP Multipath
B. eBGP Multihop
C. BGP Synchronization
D. Public AS numbers
Answer: B
Explanation
The eBGP multihop allows a neighbor connection between two external peers that do not have direct connection. The multihop is only for eBGP and not for iBGP. For example, in the topology below router A wants to establish neighbor relationship with the loopback0 of router B (to allow load balancing), which does not have direct connection so it must use “ebgp-multihop”
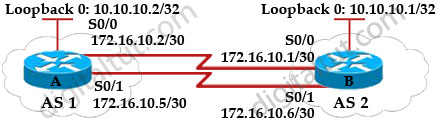
For your reference, the full configurations of both router A & B are shown below:
A# int loopback 0
ip address 10.10.10.2 255.255.255.255
router bgp 1
neighbor 10.10.10.1 remote-as 2
neighbor 10.10.10.1 ebgp-multihop
neighbor 10.10.10.1 update-source loopback 0
network 10.10.10.2 mask 255.255.255.255
ip route 10.10.10.1 255.255.255.255 172.16.10.1
ip route 10.10.10.1 255.255.255.255 172.16.10.6 |
B# int loopback 0
ip address 10.10.10.1 255.255.255.255
router bgp 2
neighbor 10.10.10.2 remote-as 1
neighbor 10.10.10.2 ebgp-multihop
neighbor 10.10.10.2 update-source loopback 0
network 10.10.10.1 mask 255.255.255.255
ip route 10.10.10.2 255.255.255.255 172.16.10.2
ip route 10.10.10.2 255.255.255.255 172.16.10.5 |
Note: If router B wants to establish neighbor relationship with the directly connected interface of router A, it only needs these commands:
B#
router bgp 2
neighbor 172.16.10.2 remote-as 1 |
But notice the traffic from router B would be sent to 172.16.10.2 interface only and load balancing would not take place.
(Reference: http://www.cisco.com/en/US/tech/tk365/technologies_tech_note09186a00800c95bb.shtml)
Question 8
Which statement is true about IBGP routers?
A. They must be fully meshed.
B. They can be in a different AS.
C. They must be directly connected,
D. They do not need to be directly connected.
Answer: D
Question 9
Refer to the exhibit. On the basis of the configuration that is provided, how would the BGP updates that come from router R1 be replicated inside autonomous system 65200?
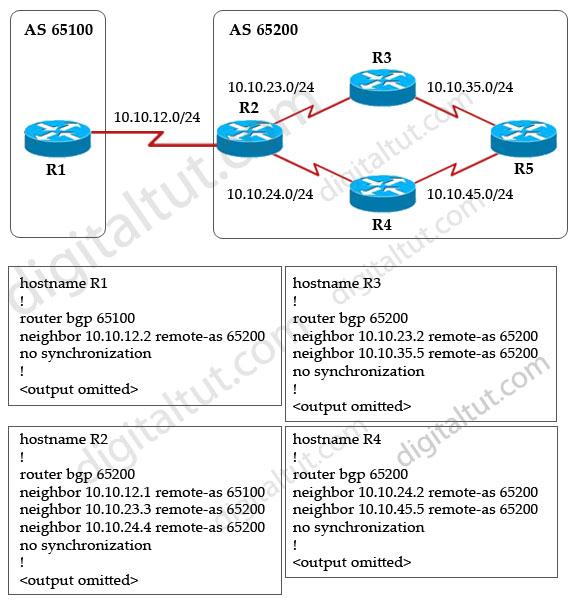
A. All BGP updates that are received on router R2 will be sent to routers R3 and R4. Routers R3 and R4 will then forward those BGP updates to router R5.
B. All BGP updates that are received on router R2 will not be sent to routers R3 and R4.
C. All BGP updates that are received on router R2 will be sent directly to router R5.
D. None of the BGP updates that are received on router R2 will ever be received by router R5.
Answer: D
Explanation
All BGP updates that are received on router R2 will be sent to routers R3 and R4 but R3 & R4 will not forward those BGP updates to R5. This is called the BGP split-horizon rule (which states that a route learned from one IBGP neighbor will not be advertised to another IBGP neighbor) -> A is not correct.
The BGP updates received on router R2 will be sent to R3 and R4 without violating the BGP split-horizon rule because R2 receives updates from an EBGP (R1), not IBGP -> B is not correct.
From the configuration of R2, we learn that R2 did not establish neighbor relationship with R5 so they are not neighbors -> no BGP updates will be sent from R2 to R5 -> C is not correct.
The BGP split-horizon rule prevents updates received on R2 from being sent to R5 -> D is correct.
Question 10
The 192.168.0.0 network is not being propagated throughout the network. Observe the BGP configuration commands from the advertising router. What is the reason the 192.168.0.0 route is not being advertised?
router bgp 65111
neighbor 172.16.1.1 remote-as 65111
neighbor 172.16.2.1 remote-as 65112
network 192.168.0.0
network 10.0.0.0
!
ip route 192.168.0.0 255.255.0.0 null0 |
A. The network 192.168.0.0 statement is missing mask 255.255.0.0
B. The network 192.168.0.0 statement is missing mask 0.0.255.255.
C. The network 10.0.0.0 statement is missing mask 255.0.0.0.
D. The network 10.0.0.0 statement is missing mask 0.255.255.255.
E. The auto-summary configuration is missing.
Answer: A
Explanation
The “network” statement in other routing protocols (EIGRP, OSPF, RIP…) is used to enable routing protocol on the interfaces within that “network” statement. But in BGP, the function of a network statement is to tell the router to search the IP routing table for a particular network, and if that network is found, originate it into the BGP database. But notice that you must have an exact match in the IP routing table to appear the network in the BGP routing table (in this case we don’t see the auto-summary command so we suppose it is disabled in this case). For example:
+ network 10.10.10.0/8 will appear in BGP if network 10.10.10.0/8 appears in the IP routing table.
+ network 10.10.10.0/24 will appear in BGP if network 10.10.10.0/24 appears in the IP routing table.
Therefore, in this question the static route “ip route 192.168.0.0 255.255.0.0 null0” was used to put a route to 192.168.0.0/16 into the routing table (although it points to Null0 but this command really makes that route appears in the routing table). But the “network 192.168.0.0” statement tells the router to lookup network 192.168.0.0/24 (if the network statement under BGP-mode does not specify a subnet mask, the default subnet mask of that class will be used). The router only finds network 192.168.0.0/16 -> The network 192.168.0.0 is not being propagated throughout the network because of the mismatch of the subnet mask -> A is correct.
Just for your information, in fact we have to suppose there is no entry of the network 192.168.0.0/24 exist in the routing table except the static route “ip route 192.168.0.0 255.255.0.0 null0”. If such an entry exists (for example, a directly connected entry like “C 192.168.0.0/24 is directly connected”) then the router still advertises it with the “network 192.168.0.0” (without mask 255.255.0.0) command.